Issue Post: https://github.com/nvaccess/nvda/issues/18186
My fixes commits: https://github.com/nvaccess/nvda/pull/18217/commits
Understanding the Issues
After the first contribution, I decided to challenge myself and work on an issue outside of the first-good-issue pool.
NVDA was announcing certain HTML elements like <header> and <footer> as “grouping,” even when they weren’t intended to serve as ARIA landmarks. This became especially confusing when these elements included an aria-label, because users would hear something like “grouping, header” — even though the element wasn’t a navigable landmark or meaningful region in the page structure.
This issue highlighted a disconnect between how web developers structure HTML and how NVDA interprets those structures using accessibility APIs like IAccessible2 (IA2). NVDA relies on semantic cues like role, tag, and container-tag to determine how to present each element to screen reader users. Unfortunately, when the element’s role was mapped to GROUPING, NVDA assumed it was meant to be treated as a “Groupbox”, and read it aloud as such.
The result? Redundant or misleading screen reader output that could hinder — rather than help — navigation and comprehension for blind users.
To address this, I had to deeply understand:
- How NVDA uses IA2 attributes like
"tag"and"container-tag"to interpret element semantics - Where in NVDA’s code these mappings are decided (in the Chromium object overlays)
- And how to distinguish between true groupings and structural elements like
<header>and<footer>that are not meant to be landmarks
Understanding this subtle accessibility nuance was key to proposing a clean, targeted fix — one that respects NVDA’s internal logic while improving clarity for end users.
Solving the Issues
First I looked for how roles like sectionheader or grouping are derived from web elements or ARIA roles. I found the following code in source > virtualBuffers > _init_.py.
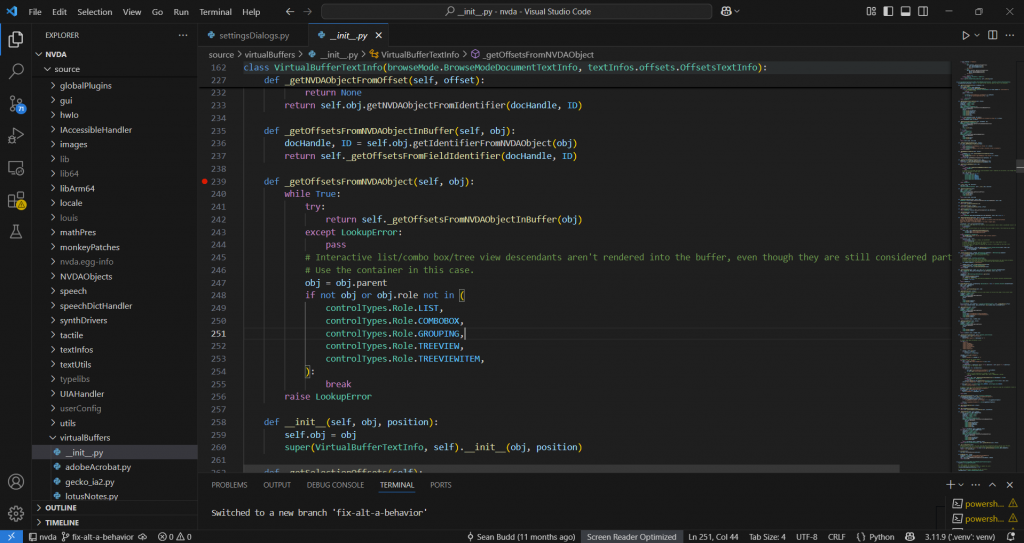
From this part of the code I could see that it’s trying to find text offsets in the virtual buffer that correspond to an NVDA object (like a button, heading, or landmark).
If that fails (LookupError), it walks up the parent tree to find a renderable container (like a list or group).
It only continues walking up if the role is in this set:
- controlTypes.Role.LIST,
- controlTypes.Role.COMBOBOX,
- controlTypes.Role.GROUPING,
- controlTypes.Role.TREEVIEW,
- controlTypes.Role.TREEVIEWITEM
This means these roles are not directly rendered, and NVDA looks for their containers instead.
Then I looked into source > NVDAObjects > IAccessible > ia2Web.py and found this section:

This is where NVDA decides how to interpret IA2 web elements. Before adding any code, I need to confirm:
- They have
IA2Attributes "tags"as<sectionheader>and<sectionfooter>. - They are not inside
"container-tag" "main" (not a landmark).
Groupbox is what makes <sectionheader> and <sectionfooter> fall into <grouping>.
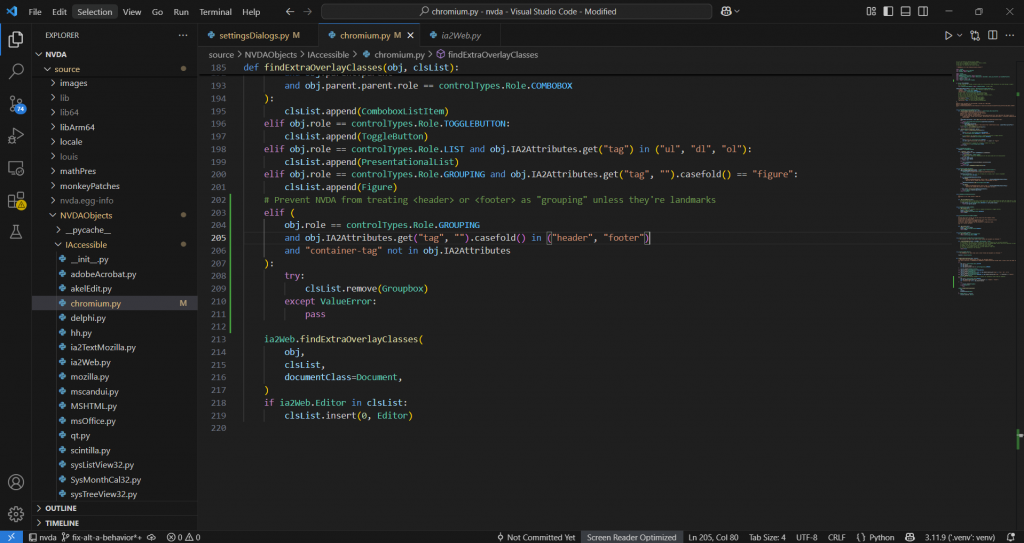
However if I make change in ia2Web.py, it will apply to all IAccessibility2 browsers. Therefore I decided to look into chromium.py as this is where <sectionheader> and <sectionfooter> are inplemented. I spot the part where it mentioned grouping in chromium.py:

Here it checks for obj.role, obj.IA2Attributes.get("tag", ""), where "tag" is the key we’re looking for, and the empty string is the default return value if the key doesn’t exist, and .casefold() for reliable and inclusive comparison. Once it satisfy all of the above, it will be removed from (Groupbox), therefore, won’t be indentified as grouping.
Creating Pull Request
Writing Comments for the Pull Request.
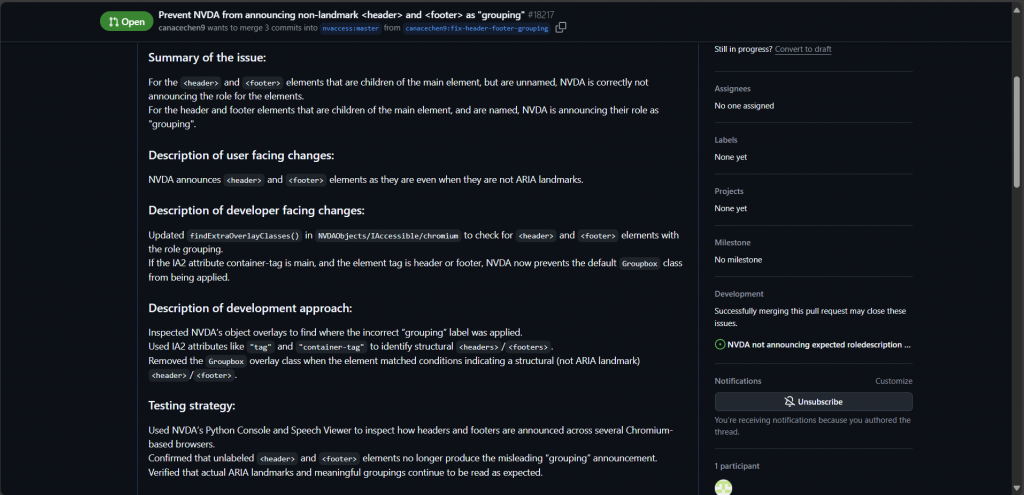
Waiting for Review & Feedback
Leave a Reply